Multi-Instance GPU on Kubeflow and its Performance
Multi-Instance GPU
Multi-Instance GPU is a feature of NVIDIA data center GPUs for virtualization, e.g., the A100 supports up to 7 instances and the A30 up to 4 instances. This guarantees separation and isolation of compute and memory resources for multi-tenancy and parallelization if one task cannot utilize a GPU fully. This post was tested with an A30 GPU.
More details at https://docs.nvidia.com/datacenter/tesla/mig-user-guide/index.html.
Multi-Instance GPU on Kubeflow
MIG supports Kubernetes and therefore also Kubeflow. The easiest way is to use the GPU operator framework to handle all GPUs described at https://docs.nvidia.com/datacenter/cloud-native/gpu-operator/gpu-operator-mig.html.
Following up the post Single Node Kubeflow cluster with Nvidia GPU support, we install the operator with
curl -fsSL -o get_helm.sh https://raw.githubusercontent.com/helm/helm/master/scripts/get-helm-3 && chmod 700 get_helm.sh && ./get_helm.sh
helm repo add nvidia https://nvidia.github.io/gpu-operator && helm repo update
helm install --wait --generate-name -n gpu-operator --create-namespace nvidia/gpu-operator --set mig.strategy=single
Important difference is the mig.strategy option, setting it to single configures the same configuration on all GPUs on the host. Other possibilities are none, to disable it, and mixed for more complex variations on the hosts.
Before the operator configures the GPUs, a profile is required, default profiles are in the config map default-mig-parted-config, we can list with
kubectl describe configmap default-mig-parted-config -n gpu-operator
Name: default-mig-parted-config
Namespace: gpu-operator
Labels: <none>
Annotations: <none>
Data
====
config.yaml:
----
version: v1
mig-configs:
all-disabled:
- devices: all
mig-enabled: false
...
# A30-24GB
all-1g.6gb:
- devices: all
mig-enabled: true
mig-devices:
"1g.6gb": 4
...
We test the profiles all-disabled, which just configures the GPU as a normal GPU, and all-1g.6gb, which virtualizes the physical GPU in 4 GPUs, each with 6 GB of RAM.
Setting the profile as a label with
NODENAME=node
kubectl label nodes ${NODENAME} nvidia.com/mig.config=all-1g.6gb --overwrite
triggers the mig-manager, which in turn activates and configures the GPUs.
MIG Performance
The performance of the virtualization is compared to the consumer GPUs RTX 3080 and RTX 3090 and between a virtualized and non-virtualized A30 instance with one fourth of the computing power and memory size. The GPUs are placed in different systems, but use Ubuntu 20.04 with Kernel 5.13 and Tensorflow 2.8.
All GPUs were tested using the ai-benchmark ai-benchmark alpha that runs different tests and returns a device score shown in the figure.
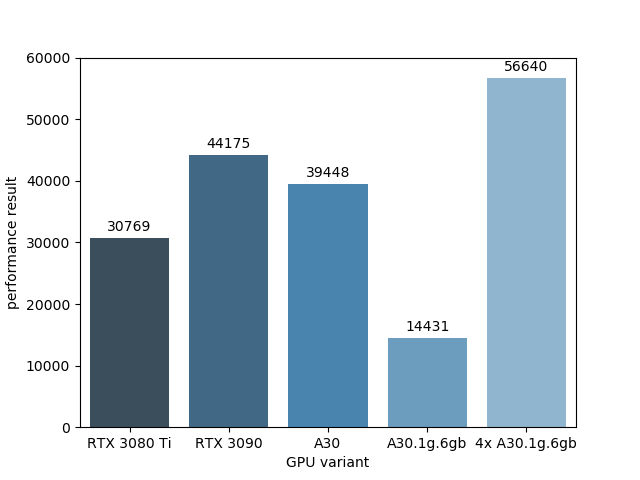
The non-virtualized A30 GPU ranges between a RTX3090 and RTX3080 Ti, activation of MIG can improve the performance if all four virtualized instances can be utilized in parallel. We run the benchmark in parallel on all four virtualized A30 instances of one GPU and achieve a score in sum that is significantly higher than achieved by the RTX3080 Ti and RTX3090.
Delete the GPU operator
Delete the operator, related cluster policy, and labels:
helm uninstall -n gpu-operator $(helm list -n gpu-operator | grep gpu-operator | awk '{print $1}')
kubectl delete crds clusterpolicies.nvidia.com
for i in `kubectl get node -o json | jq '.items[].metadata.labels' | grep nvidia | cut -f 1 -d ':' | sed 's/\"//g' | sed 's/[[:space:]]//g'`
do
echo $i
kubectl label nodes ${NODENAME} ${i}-
done